NLP on PDF Data
Overview
- This is a series of works on analyze PDF files, each module and its function are listed below.
- All modules are integrated into streamlit app, which provide some selectable options
-
Local run
-
Clone repository to local doc
- Intall all the dependencies
pip install -r requirements.txt - Run streamlit app
streamlit run app.py
-
1. Import Data
- Import from folder: using pypdf2 to conduct text extraction, might not be accurate but quite fast.
- Import from file: read csv/pickle type files that have include text data inside.
2. Data Preparation
- Including clean puncatuation, remove stop word, and lemmatization.
- Tokenization(considering bigrams).
- Using spaCy to do POS filteration.(e.g. NOUN, ADJ, VERB…etc)
3. Topic Clustering
- 1.Using bag of words to conduct LDA
- 2.Using Tf-idf to conduct LDA
4. Visualize 🚧
- 1.Coherence value
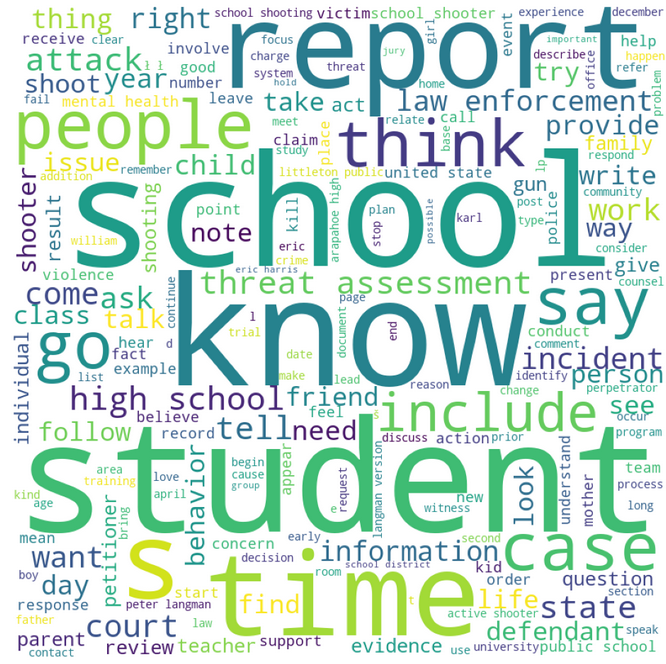
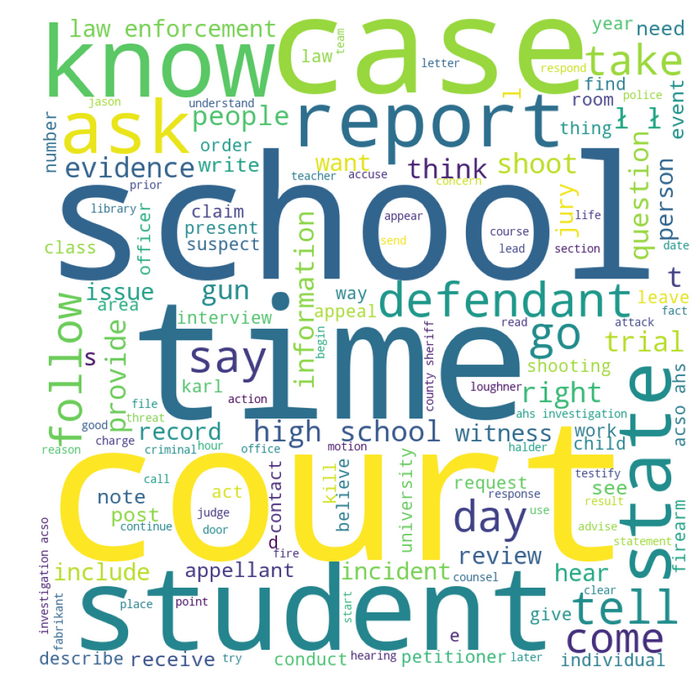
- 2.Wordcloud